

Text Mining : Classification Automatique de textes
La catégorisation ou classification automatique de textes est l’investigation par ordinateur des propriétés linguistiques des caractères ASCII qui forment le contenu textuel d’un document numérique. Dans le cadre de l’apprentissage automatique, nous nous référons à la littérature du traitement statistique du langage « naturel » (Natural Langage Processing, NLP).
Le processus de classification d’une collection de textes consiste à étiqueter chaque texte avec une ou plusieurs classes (catégories) prédéfinies par le biais d’un algorithme d’apprentissage automatique (Machine Learning / Deep Learning).
Article écrit par Julien MILON, Consultant, membre de la BCOM Data chez HeadMind Partners Digital
Cas d’utilisation de la classification automatique de textes
Pourquoi catégoriser/ étiqueter des textes ou documents textuels ?
La classification de texte a pour fonction première de définir le contenu d’un document en seulement quelques mots. Cet étiquetage va permettre notamment de faciliter des recherches fines par filtre sur un corpus de documents textuels.
On compte bon nombre d’applications de la classification automatique de texte suivant le contexte. Parmi les plus répandues, la classification automatique de texte va permettre par exemple de :
- faire des recherches par filtres, notamment dans le cadre de recherches web ou sur un grand corpus de documents ;
- transférer des documents de manière automatique aux bons services d’une entreprise en fonction du contenu d’un texte ;
- faire de l’analyse de sentiment.
Méthodologie
Dans ce processus, un algorithme est d’abord conçu, puis il est entraîné avec un ensemble de caractéristiques spécifiques, par exemple les occurrences de mots ou encore les distributions de thèmes dans un document. Une fois entraîné, l’algorithme est utilisé pour étiqueter de nouveaux textes. Ces derniers sont différents des textes utilisés lors de l’entraînement. L’algorithme est évalué sur le nombre d’erreurs de classification obtenues lors de la phase d’apprentissage et lors de la phase de test.
La conception d’un algorithme de classification se découpe donc en quatre grandes étapes :

1. Définition des Classes/Catégorie d’un jeu d’apprentissage
Pour faire de la classification de texte, l’algorithme a besoin d’un corpus de textes d’apprentissage, c’est-à-dire un ensemble de texte possédant déjà une ou plusieurs catégories. Dans un premier temps il faut donc définir l’ensemble des catégories ou étiquettes que l’on souhaite attribuer aux documents en fonction de notre besoin et contexte (analyse de sentiment, classification par thématique…).
Une fois l’ensemble des catégories définies, l’ensemble des textes du corpus d’apprentissage devra avoir une ou plusieurs catégories. Ce travail est fait “manuellement”.
Ce corpus servira de base d’apprentissage à un algorithme d’apprentissage automatique. C’est-à-dire que l’algorithme va construire un modèle (dépendant de la méthode d’apprentissage choisie) pour définir des liens, des relations entre documents d’une même catégorie et ce qui différencie les catégories ente elles.
2. Vectorisation : transformation d’un texte en Vecteur
Un ordinateur ne fonctionne pas comme un cerveau humain et les algorithmes d’apprentissage automatique non plus. Un texte n’est ici qu’une suite de caractères binaires et n’a pas de sens pour un algorithme. Pour donner du sens à un texte, du point de vue de l’algorithme d’apprentissage, il faut transformer le texte en vecteur.
Il s’agit de l’étape la plus importante des algorithmes de classification de texte et de l’ensemble des projets de NLP. Il existe plusieurs méthodes :
a) Bag of Word / Bag of ngrams (Méthode par Fréquence)
Exemple de librairie en Python : sklearn.feature_extraction.text
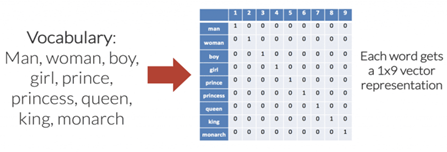
Il s’agit d’un réseau de neurones “simple”. Le principe est de transformer une phrase ou un texte en fonction de l’apparition ou du nombre d’apparitions de mots d’un vocabulaire prédéfini. Dans l’exemple ci-contre, le vocabulaire choisi est ‘man’, ‘woman’, ‘boy’, ‘girl’, ‘prince’, ‘princess’, ‘queen’, ‘king’, ‘monarch’. Le mot prince serait donc représenté par le vecteur [0,0,0,0,1,0,0,0,0].
Pour transformer une phrase, on se base donc sur le nombre d’apparition des mots clés définis dans le vocabulaire.
La phrase ‘This man is not the prince, it is the king’ serait symbolisée par le vecteur [1,0,0,0,1,0,0,1,0] ou bien encore ‘Boy, boy, boy’ serait représentée par [0,0,3,0,0,0,0,0,0].
Cette méthode a l’avantage d’être très simple et peu coûteuse d’un point de vue algorithmique. Mais il faut bien choisir le vocabulaire de représentation, en fonction du contexte et de son besoin, mais aussi du vocabulaire du cursus d’apprentissage.
Une autre méthode permettrait de donner plus de sens à la transformation vectorielle d’un texte et permettrait aussi une meilleure classification.
b) Word Embedding (Deep Learning)
Exemple de librairie en Python : Work2Vec
Il s’agit d’un Réseau de Neurone Récursif (Recurrent Neural Network) qui va rassembler les mots par rapport à leur « sens » dans un corps de texte. Le réseau de neurones de type ‘Word Embeddings’ va analyser chaque mot en fonction du ou des mots qui le précèdent.
Ce réseau de neurones va progressivement construire des liens entre les mots possédant des caractéristiques communes comme le sens ou l’entité d’un mot (nom commun, verbes, …).
Ces rassemblements de mots peuvent être vus comme des catégories de mots, mais parfois ils peuvent n’avoir aucun sens pour un être humain. Un mot ne sera donc plus représenté par un vecteur unitaire [0,0,0,1, …,0] d’un vocabulaire défini, mais par un pourcentage d’appartenance aux « classes » qui auront été créées par le réseau de neurones.
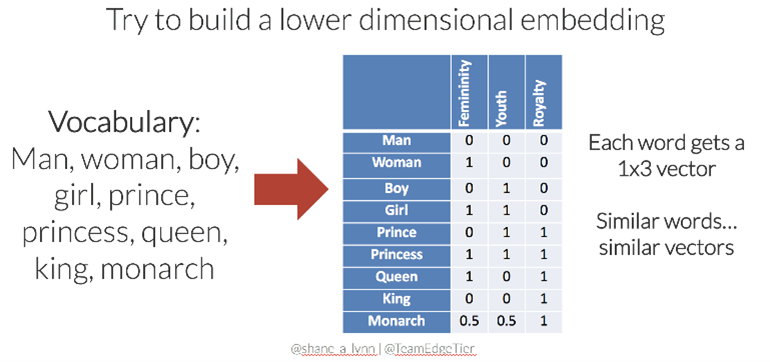
Dans l’exemple précedent, le réseau de neurones aura créé 3 classes en se basant sur les mots ‘man’, ‘woman’, ‘boy’, ‘girl’, ‘prince’, ‘princess’, ‘queen’, ‘king’, ‘monarch’. L’algorithme ne nomme pas les classes qu’il crée mais en fonction des rassemblements fait un Homme pourrait déduire qu’il s’agit des catégories suivantes : Gender , Youth et Royalty.
3. Mise en place du modèle de catégorisation
Une fois les caractéristiques extraites, plusieurs algorithmes d’apprentissage peuvent être utilisés pour la classification automatique de textes. Pour citer les plus connus :
- algorithme de Rocchio’s ;
- méthode des K plus proches voisins ;
- classification naïve bayésienne ;
- arbres de décision ;
- séparateurs à vastes marges (SVM) ;
- forêts aléatoires.
Il s’agit d’évaluer l’algorithme d’apprentissage qui mettra en place le meilleur modèle pour répondre à un besoin. Le modèle est ce qui va définir les critères d’appartenances d’un texte à une ou plusieurs catégories.
Cette phase d’apprentissage est de plus en plus simple grâce aux librairies de machine learning (Scikit-learn, Pytorch, Tensorflow parmi les plus connues en python). On privilégiera les modèles linéaires et les arbres de décisions si l’on souhaite obtenir un modèle interprétable. On optera pour les forêts aléatoires dans les autres cas. Cette étape est celle de création de notre modèle.
Ces modèles présentent l’avantage de s’apprendre rapidement et de fonctionner sur tous types de données, discrètes ou continues. Les forêts aléatoires sont également robustes au surapprentissage : elles ne font pas créer un modèle fonctionnel sur notre jeu d’apprentissage et non fonctionnel sur un autre. Être robuste au surapprentissage permet d’avoir un modèle qui fonctionne de manière générale avec n’importe quel jeu de données autre que celui d’apprentissage.
4. Prédiction
L’étape de prédiction consiste à appliquer le modèle d’apprentissage construit lors de l’étape 3, sur les textes ou documents que l’on souhaite classer.
Solutions
Il existe de nombreux logiciels permettant la classification de textes. Les plus performants sont ceux développés par Google et Amazon car ils possèdent un corpus d’apprentissage astronomique, par exemple “Amazon Comprehend” sur AWS.
Pour développer ses propres algorithmes de classification de textes, il existe aussi des librairies facilitant la construction de son algorithme. NLTK en Python (https://www.nltk.org/) en est un exemple.
Conclusion
Chez HeadMind Partners, nos consultants Data sont spécialisés dans les nouvelles technologies telles que l’intelligence artificielle et la data science. La classification de textes et le text mining de manière générale offrent à nos clients de nouvelles perspectives d’analyse de données, que ce soit dans un cadre d’analyse de besoin client ou pour faciliter le travail de ses collaborateurs. Lancez-vous dans le text mining et l’analyse de vos fichiers et données textuelles !
Sources
- Livre : Sami Laroum, Nicolas Béchet, Hatem Hamza, Mathieu Roche. Classification automatique de documents bruités à faible contenu textuel. Article de thèse, 2009.
- Site Web : Javaid Nabi « Machine Learning — Text Processing». Année. [publié le 13/09/18]. Disponible à l’adresse : https://towardsdatascience.com/machine-learning-text-processing-1d5a2d638958
- Site Web : Mayank Jain « NLP: From Watermelon Boxes to Word Embeddings». Année. [publié le 23/04/20]. Disponible à l’adresse : https://towardsdatascience.com/natural-language-processing-from-watermelon-boxes-to-word-embeddings-4eb32e7dfd8a
- Mémoire de M. Aouine Mohammed http://dspace.univ-guelma.dz:8080/xmlui/bitstream/handle/123456789/429/Memoire.pdf?sequence=1&isAllowed=y




